Our organization curates and standardizes individual patient data that is shared with us from data generators around the world to a single format so it can be combined and used in IPD meta-analysis when requested via a Data Access Committee.
It is important to us to be able to provide evidence of data reuse so as to acknowledge data generators each time their dataset is requested and shared.
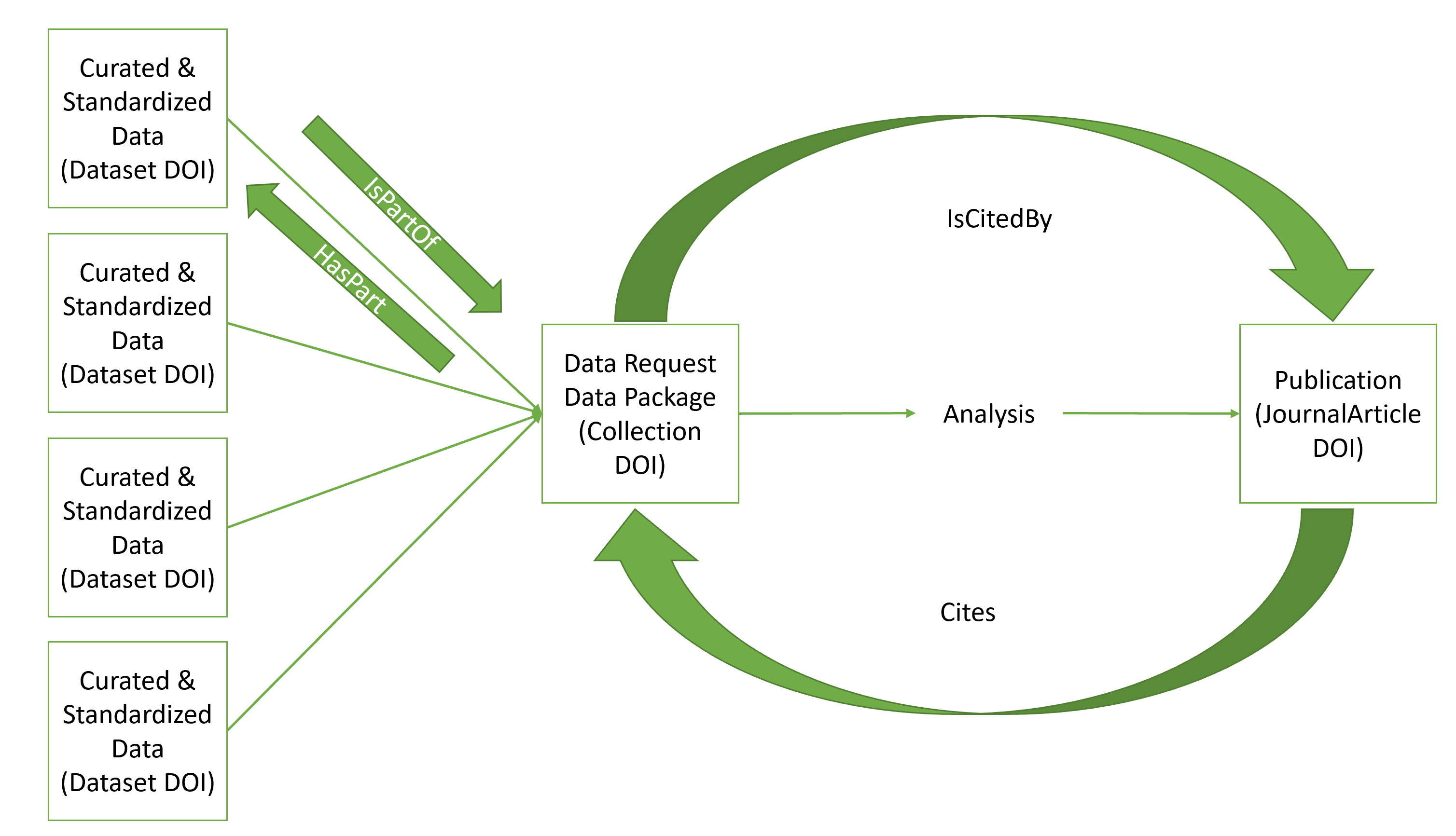
We generate a DOI for each dataset shared with us.
We generate a DOI for each data package/dataset we release when data is requested (sometimes these packages contain over a hundred datasets).
I have tried to illustrate this in the attached image.
Question: What is the best way to allow citations for the underlying datasets that make up the data packages?
We originally thought we would have data requestors cite each underlying dataset, but sometimes that amounts to 100+ DOIs and have run into issue with journals not allowing that many references.
Our initial proposal is to make the data package a Collection DOI and use the “HasPart” and “IsPartOf” relationships to capture all the underlying datasets that make up the package. However, will this actually add a citation to each underlying dataset DOI each time the data package DOI is used? If not, do you have any thoughts or suggestions as to how we could best ensure data generators get a citation each time their data is used in a publication?
@kalynn
I do not have a solution but maybe reaching out to Crossref (@epentz) might be worthwhile. Looking at the Event Data, it seems “HasParts” is excluded. Here is another pointer on Event data. So this means in your case only the Collection DOI will get the citation.
Hi @kalynn, we at Technical University of Vienna and University of Vienna actually currently work on a prototypical solution to this problem and allow persistent identification of arbitrary queries to a specific dataset. See the prototype (public) sandbox at https://dbrepo.ossdip.at. We would like to know more about your use-case and arrange a meeting via PN. This problem is relevant for multiple domains, not only the meta-analysis studies in medicine.
The approach you describe will not add a citation to the underlying dataset DOI each time the data package/collection DOI is cited. Currently, citations don’t “cascade” downwards, so each relationship would have to be added directly between the publication DOI and the dataset DOI. This can be added either in the publication DOI metadata or the dataset DOI metadata. However, as you note, this may be too many references to add from the publication side.
Since your organization can update the dataset DOI metadata, one approach to adding citations to the dataset DOIs would be to use DataCite Event Data to monitor the data package/collection DOI for citations. Whenever the data package/collection DOI is cited, you could use the DataCite REST API to update the corresponding dataset DOIs with the additional citation. You will want to add a RelatedIdentifier with one of the relationTypes used for citations: IsCitedBy, IsReferencedBy, or IsSupplementTo. Note that you’ll want to use RelatedIdentifier here, not RelatedItem, for the citation to count.
If you were to implement this, for example with a Python script, the steps would be:
For each data package/collection DOI:
Get all citations of that DOI from Event Data
For each citation:
Get the DOI of the publication it is cited by
For each dataset DOI that is part of the data package/collection - related with HasPart/IsPartOf:
Add a RelatedIdentifier to link to the publication DOI (IsCitedBy/IsReferencedBy/IsSupplementTo)
Let me know if you have any questions about this approach, and I’d be happy to help!